edit: botlane has been updated to include Senna, Kalista, Mel, and Brand
I’ve always been quite fascinated by the conversation surrounding champion identities; from LS’s MTG colouring approach, to Randominum’s classes and subclass guides, to whatever this witchcraft is. I’ve always been content to parrot the ideas I’ve picked up without really investigating them for myself. But then, I came across the original Botlane Ecosystem post in 2024, and it really sparked my interest. Ever since, I’ve wanted to take a crack at it using my data science background. And finally, here it is.
Champion Identities
So, what is a “Champion Identity”? To me, a champion identity is the specific way a champion goes about winning a game. An enchanter wins by buffing and protecting a carry to let them deal more damage; an assassin wins by killing squishies with limited opportunity for retaliation; etc. I think an accurate understanding of champion identities is valuable because they enable us to have informative conversations, for entire subsets of champions, about the patterns and thought processes we should have when:
- We pick them
- We pick with or against them
- We play them
- We play with or against them
Building Representations
If you haven’t lived under a rock, you’ve probably tried a large language model like ChatGPT or Claude in the past few years. These models work by predicting the next word based on the sequence of words that came before it. While training for that task, the model learns internal representations of words in the form of numerical vectors called embeddings. These embeddings tend to exhibit some latent structure; for example, words with similar meanings tend to have embeddings that are located close to one another in this space. (I highly recommend this brief explanainer on embeddings done by 3Blue1Brown).
Our Approach
For our problem, we also wanted to create a model (a neural network for those more technically inclined) that could learn representations for champions in League of Legends. But what task do we train it to do to learn these representations? We needed a task that serves as a proxy (not in the Baus sense) for understanding how a champion goes about winning a game. Note that different champions are:
- Better against certain champions than others
- Stronger at certain points in the game than others
- Likely to have different fighting patterns
To reflect these features, we decided to train our model to use the champions in each role on both teams to predict:
- How likely are they to win at different times?
- How long will the game last?
- How much damage will they deal?
- How much damage will they take?
Our Model
Using games from Diamond+ in Season 16, we were able to train a model that could predict the overall outcome of matches with approximately a 56% accuracy. Pretty good, given there are factors that contribute to winning more than draft (namely, player skill differences). Here is our model in action, predicting the win rate (orange line) and likelihood of ending (purple line) across various game lengths:

Final Embeddings
Now, did the model learn any meaningfully interpretable structure when we look at how it internally represented champions for our task? Impressively, it did! After removing the direction in the representation that most closely correlated to raw winrates (which is a feature the model learned, but we consider champion strength separate from champion identity), we’re left with some embeddings that make a lot of sense. These embeddings are represented in hundreds of dimensions, but there are 3 main ways we can visualise them
Dimensionality Reduction
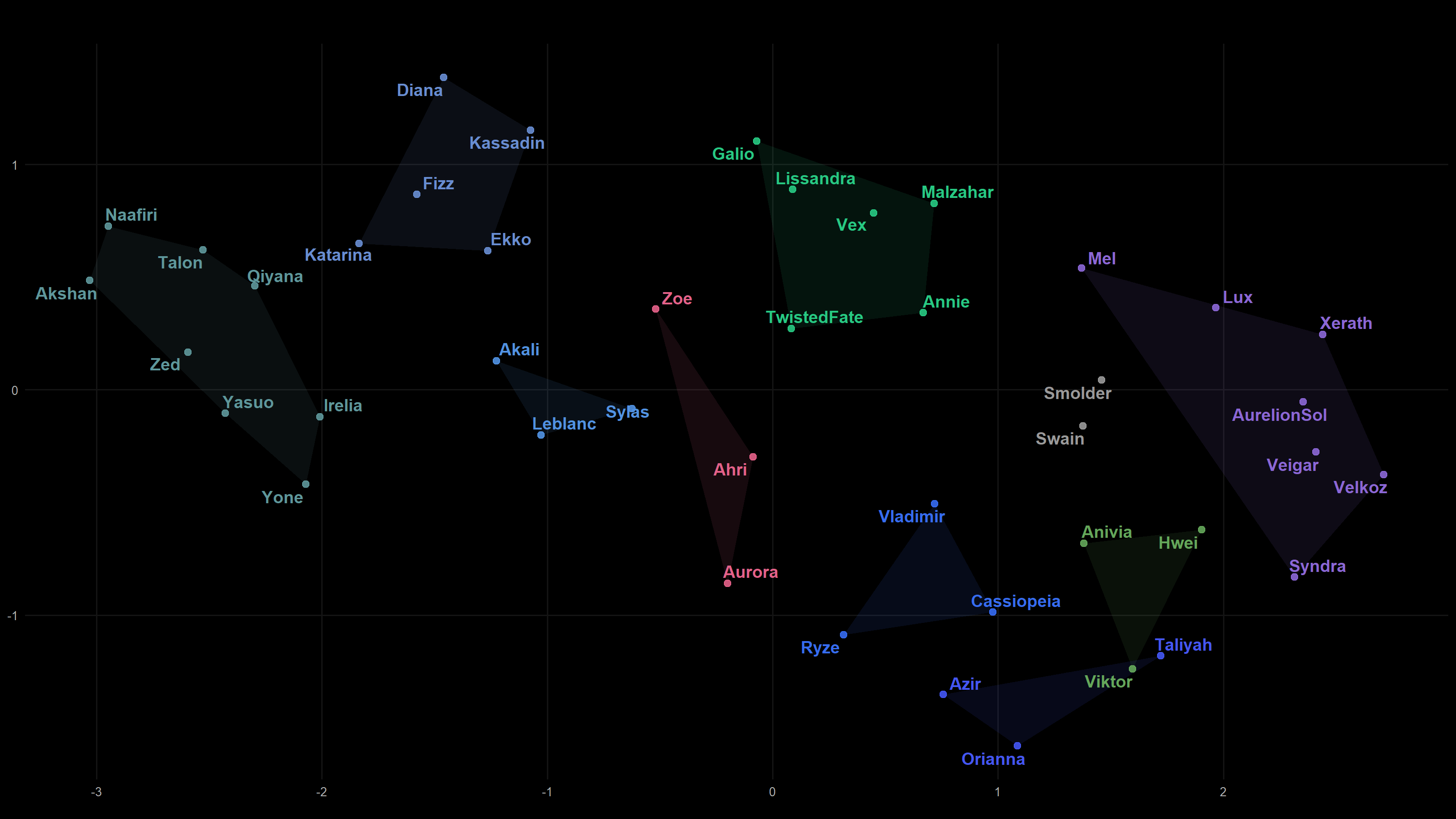
First, we can try to visualise them within a dimensional space that’s more intuitive for us to interpret. Inevitably, some information is lost in this reduction. But, by applying an algorithm called Uniform Manifold Approximation and Projection (UMAP), we try to preserve the structure by keeping points that are close in the original space close in the embedding, while also maintaining broader cluster separation as much as possible.
You can see that some “directions” in these visualisations may represent aspects or alignment with some identity for these champions, though the “directions” may have been curved by the dimensionality reduction process. Based on their position along these directions, you can interpret whether a champion is more aligned with one identity than another. Below, we’ve animated 3d plots for champions in each role. We’ve also coloured clusters of champions that were close together for your reference; you can think of these as champion classes.
Top Lane

Jungle

Mid Lane

Bot Lane

Support

Similarity Maps
Second, we have similarity maps that indicate how similar or different two champions are. These are especially valuable because if two champions are similar, they likely share some defining aspect of their gameplay that should inform our approach to dealing with them. Below, we have the similarity maps for champions in each role.
Top Lane

Jungle

Mid Lane

Bot Lane

Support

Dendrograms
Finally, we have dendrograms, which allow us to create a class and subclass tree to classify champions and discuss certain subsets broadly. Below, we have the dendrograms for champions in each role.
Top Lane

Jungle

Mid Lane

Bot Lane

Support

Acknowledgements
Huge thanks to Joseph Zinski for inspiring me, helping me with this project, and letting me use his platform to share this.
Appendix
Hey guys, I’m Allen, a recent computer science graduate. From now on, I’ll also be contributing to the blog to bring you guys more insights!
Here are some 2d version of the UMAP embeddings since more plots never hurt anyone.




Leave a Reply to AnonymousCancel reply